1. Node
1.1. 前言
进阶的条件和难点:
- 到了需要进阶的时候
- 掌握了系统的学习方法论
方法:看文档 => 写demo => 分享
进阶过程中可能遇到的坑
- 对基础知识走马观花
- 后端知识基本忘光
- 缺乏产品和业务的全链路思维
- 基建不完善,面对性能问题无处下手,能力上限没有团队说服力
侧重点
源码入手,知其然、并知其所以然
紧贴时间,在实践中学习
方法论
- 重视基础知识的掌握
- 不全数据库知识和数据表设计能力
- 将开源项目的源码拉下来读一下
- 选一个频繁使用Noode的场景最为突破口
资源
书籍
- 狼书
- 深入浅出node
- nodejs实战2
1.2. 基础知识(要扎实!)
1.2.1. node的安装和版本
Mac下:
官方的安装包
Homebrew 全局安装、手动管理
NVM 方便管理版本
Windows下:
- 官方安装包、快速开始、推荐使用
- nvm-windows 不太稳定、社区维护
- Cmder 集成命令行工具(基于linux)
- WSL windows提供的内置linux运行环境
- windows Terminal 官方的下一代命令行工具
Node的版本选择:
LTS是长期稳定版本、生产环境必须用;
实验项目可以用current版本
奇数为不稳定版本,偶数稳定。
不必保持最新
模块机制
- 采用CJM/ESM来组织
- 每一个文件就是一个模块,有自己的作用域
- 一个文件里的东西都是私有的,除非export出来
- node中,模块加载是运行时同步加载的
- 模块可以多次加载,到那时运行结果会被缓存,用作接下来的加载。
npm、nrm、npx
npm是包管理工具
nrm管理npm的源
npx 执行命令、很全能
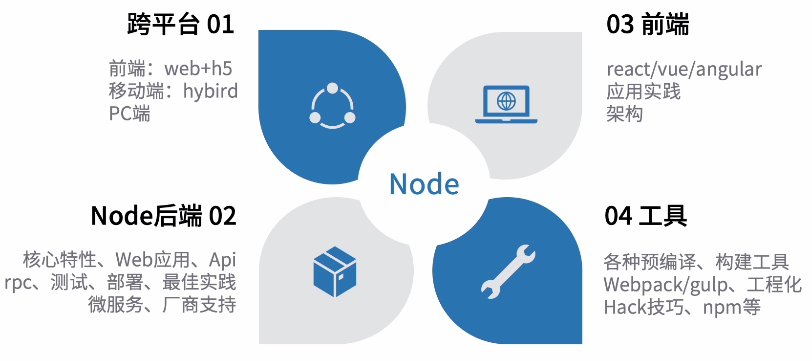
Nodejs的能力
- 跨平台:web + H5 + hybird + PC
- Node后端:Web应用、API rpc、微服务
- 前端:react、vue、angular应用实践架构
- 工具:webpack、gulp、npm等
node不适合做计算量比较大的事情、适合做吞吐量大的事情。
1.2.2. Nodejs的原生API能力
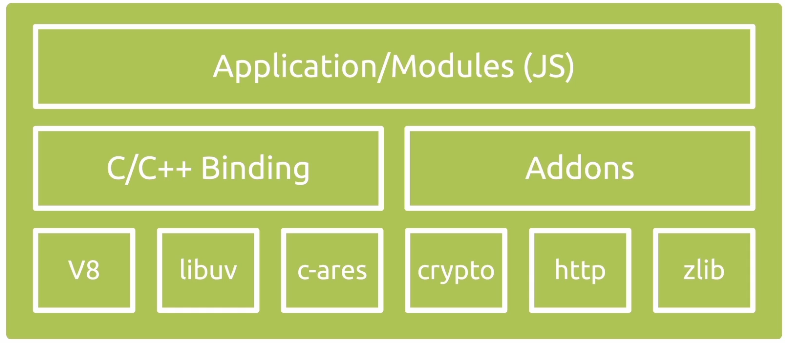
libuv:灵魂、异步任务、线程池;
binding:胶水代码、将不同语言的代码粘合在一起。
了解数据类型
Buffer-缓存 : 对象占用内存空间,不计算在进程限制上。
处理流式数据
存储需要临时占用大量内存的数据
生产者和消费者的速度通常不一致,需要暂存一些数据
buffer通过highWaterMark参数指定,默认16kb
一些方法:
from(buffer|array|string) 使用堆外内存新增buffer
from(arrayBuffer) 浅拷贝arrayBuffer,共享内存
alloc(size) 分配一个置顶大小的buffer
allocUnsafe(size) 分配一个没有初始化的buffer
流式数据会自动创建Buffer,手动创建需谨慎
- 转换格式:
字符串:编码Buffer.from(str)解码buf.toString()
JSON:buf.toJSON()
- 裁剪和拼接
Buffer.slice(),返回Buffer与原buf共享内存
buf.copy/concat,返回新的Buffer
- 比较和索引遍历
索引遍历:buf[index]\for of\IndexOf\includes等
比较:buf1.equals(buf2)
Stream流式数据
Stream提供的是抽象借口,很多模块实现了这个接口。
是为了解决异步IO问题

event/EventEmitter 事件
Error错误
- 标准的JS错误
- 底层操作的系统错我
- 用户自定义错误
- 异常逻辑的异常
错误冒泡和捕获:一般从异步方法的callback方法来捕获
所有node和js抛出的异常都是Error实例
URL 资源定位符
现在主要用WHATWG URL(H5的规范)
URLSearchParams来操作参数
global 全局变量
仅存在于模块的作用域中,相当于只在一个文件里。
__dirname、__filename、exports、module、require()
从JS过来的
console、timer、global
Node特有的
Buffer、process、URL、WebAssembly
这些数据类型的意义在于,方便我们在实现高级功能时,可以直接调用底层的东西
了解几个工具库
工具库-util
- 风格转换:promisify <=> callbackify等
- 调试工具:debuglog、inspect、format等
- 类型判断:types.isDate(value)等
工具库-assert断言
- 断言真假:assert(value,msg),match(string,reg)等
- 断言等价:scriptEqual、deepStrictEqual等
- 断言成功失败:fail、throws、rejects、ifError等
工具库-querystring
官方提供的解析和格式化url查询字符串的工具
- 查询字符串转键值对: parse
- 键值对转查询字符串:stringfy
掌握文件系统能力
OS模块:提供与操作系统相关的使用方法和属性
可以兼容的调用不同平台的底层命令,形成系统快照
cpus、platform、type、uptime、userInfo
定义操作系统级别的枚举常量
信号常量SIG、错误常量E、Windows特有的WSA、优先级PRIORITY_
fs模块:提供用于与文件系统进行交互的API
可以同步、异步交互
URI作为特殊文件也可以被fs模块使用
- 操作文件夹:mkdir、rmdir
- 操作文件:chomd、open、read、write
1.2.3. 底层机制和原理
模块机制——CommonJS
模块引用(require)、模块定义(export)、模块标识(路径)
过程:路径分析 => 文件定位 => 编译执行 => 加入缓存
- 路径分析
内置模块、文件模块
模块的查找顺序(类似于原型链):已缓存模块 - 内置模块 - 文件模块 - 文件目录模块 - node_modules模块 - (父级)
- 文件定位
根据扩展名判断 - 解析package.json - 找到入口文件 - 进入下一个(父级)模块路径
编译执行
js文件通过fs同步读取编译执行
- json文件通过fs同步读取,用JSON.parse解析并返回结果
- node文件是用c/c++写的扩展文件
还需要注入全局变量、构造上下文执行环境(闭包产生作用域,通过runInThisContext方法)
未知文件也会被当作js文件编译
- 加入缓存
「核心模块」会被登记在NativeModule._cache
「文件模块」会以字符串形式存储,等待调用
「清除缓存」通过delete.requre.cache[require.resolve(module)],当然有很多第三方模块已经封装了这个方法
CMJ和ESM
ESM:
- 静态加载模块
- 变异的时候执行代码
- 缓存执行结果
- 按需引入、节省内存(Tree-shaking)
CJM:
- 动态加载模块
- 调用的时候加载源码
- 加载全部代码
1.2.4. 网络编程能力
Socket:套接字,是底层通信,用来描述端口和主机;几乎所有的应用层都是通过socket进行通信
从何而来?对TCP/IP进行封装,并向应用层协议暴露接口调用。
TCP和UDP的不同,在于不同参数的socket实现过程不同
net/dgram模块
net是TCP/IP的node实现,提供一些用于底层的网络通信的方法
http客户端和服务端通信均依赖于socket
net.Server:TCP server,内部通过socket来实现与客户端的通信
net.Socket:本地socket的node版实现,她实现了全双工的stream接口
API:连接connet、读写write、属性bufferSize、地址address
http/https/http2模块
编写Web Server最常见的模块
Server部分继承自net.Server并对请求和相应数据进行封装方便实用。
也提供了像其他服务端发起HTTP请求的能力
进程管理

线程:单一顺序控制流程、程序执行流的最小单元
进程:计算机任务分配的最小单元
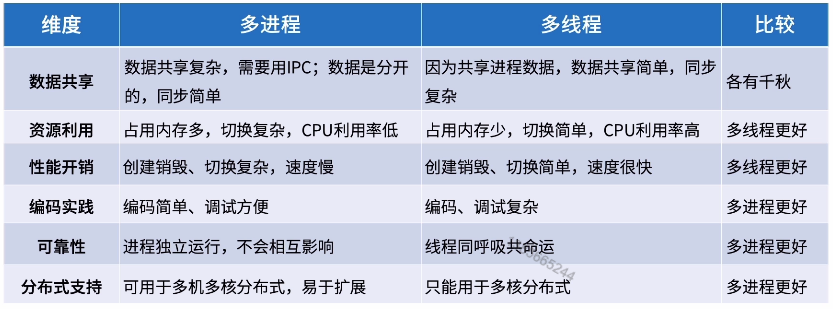
多进程vs多线程
EventLoop
EventLoop是一个程序结构,用于等待和发送消息和时间
是单线程任务排队执行的机制。
JS通过EventLoop的形式解决单线程任务调度问题
浏览器和Node的EventLoop是两个概念
Node的EventLoop
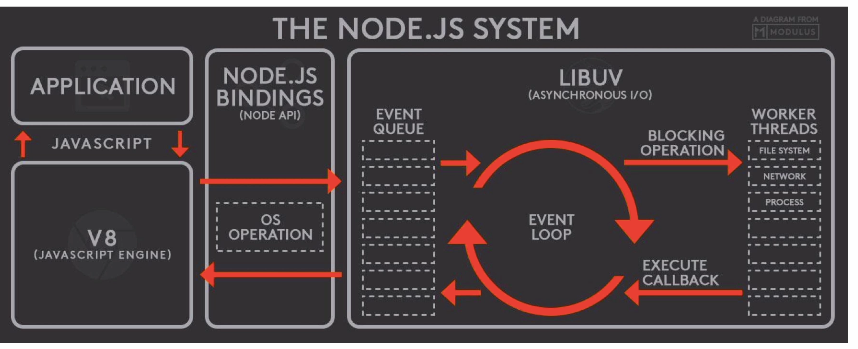
微任务:nextTick > Promise,不同微任务被放到不同的微任务队列。
「宏任务队列」的顺序:timer > I/O > check/close
在宏任务执行的间隙去清空「微任务队列」
Process
Process是一个全局对象,描述进程
是一个EventEmiter的实例,暴露了进程事件的钩子。
提供标准流输出,对应的是进程的I/O操作
console是由stdio实现,会有额外性能开销
NextTick()是把回调压入微任务队列
child_propcess/cluster子进程
child_process是Node.js的内置模块
- spawn:用于返回大量数据,例如图像处理、二进制,
- esxe:适用于小量数据,用Buffer(最大为200*1024),例如写CLI的时候
- fork:衍生新的进程,进程之间是相互独立的
cluster也是
- Worker对象包含了关于工作进程的所有的公共的信息和方法
- fork衍生新的进程,进程之间是相互独立的
- 使用主从模型轮询处理服务的负载任务,通过IPC通信
进程守护:进程挂了,可以重新启动一个。
最佳实践:该挂就挂,再自启动就好了
使用工具pm2、forever
拓展
node的事件循环https://blog.fundebug.com/2019/01/15/diffrences-of-browser-and-node-in-event-loop/
node的模块机制https://juejin.im/entry/5b4b5081e51d451984696cb7
node的进程与线程https://juejin.im/post/5d43017be51d4561f40adcf9
1.3. 实践内容
使用Express编写Restful API
编写 Web Server 测试
Web服务及Koa源码分析
使用Egg编写企业项目
1.3.1. Web Server实战
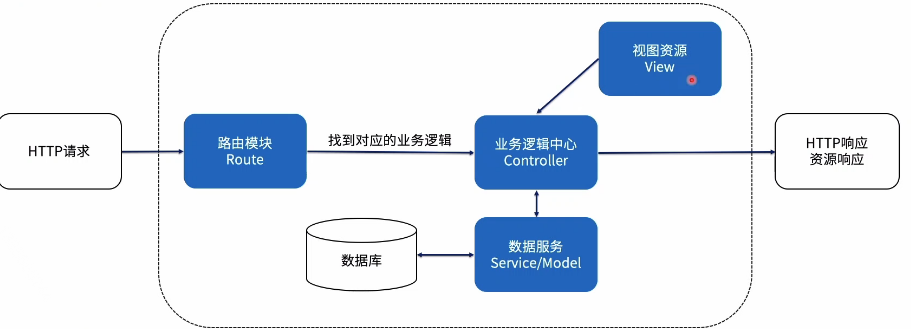
Web Server的构成:
- 处理HTTP:对HTTP的请求进行响应
- 路由管理:分别处理不同URL路径的请求,返回对应的网络资源
- 静态文件托管:对网络请求的静态资源进行响应或使用模版动态响应请求
- 文件数据存储:将请求携带的数据存储到文件或者数据库中
基本架构:
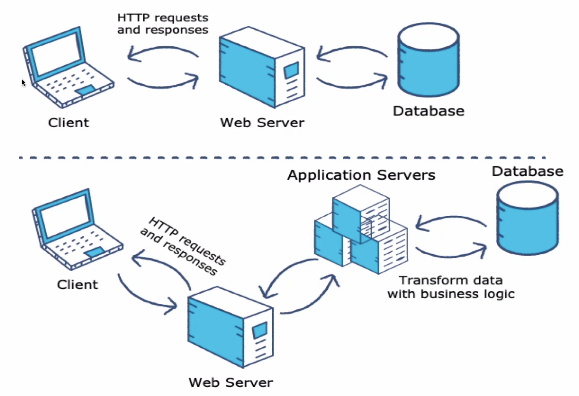
优势:
- 并发性能优势
- Javascript同构
- 生态活跃完善
- 代码移植性好
- 框架高度包容
- 社区氛围友好
1.4. Express

express的强大之处在于中间件。
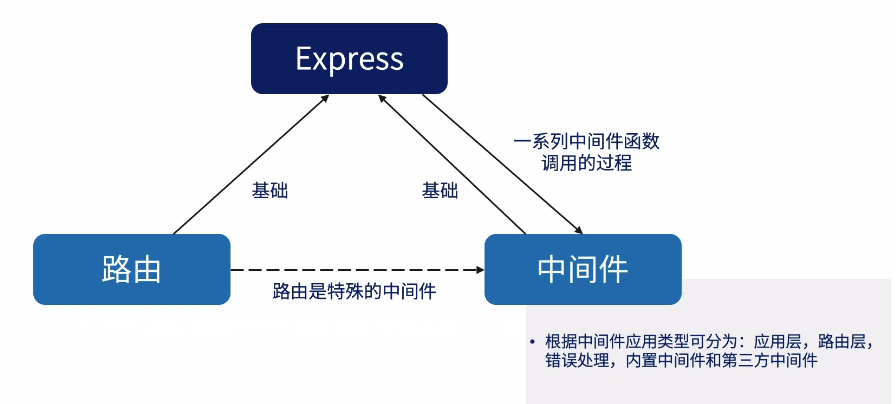
编写中间件,app.get('',()=>{})就是一个中间件。
路由机制
路由就是将HTTP动词、URL路径、模式和处理函数三折关联起来
EXpress的应用程序要从路由设计入手,将服务的能力描述出来
还刻有使用ROuter中间件
最佳实践(需要遵循的)
使用中间件压缩响应数据,在反向代理层做
避免在业务逻辑处理中使用同步阻塞操作
引入完善的基建保障,记录日志,处理异常
需要重启的时候立刻重启,保证可以自动重启
1.4.1. 邮件实践
整体流程

功能设计

1.4.2. RESTful API
基于REST架构的Web server 就称为RESTful
特点:
- URI资源定位,REST是面向资源的
- 链接资源状态,服务器生成包含状态转移的表征数据,来响应请求
- 使用HTTP已有特征,动词、状态吗、头部信息
- 统一资源规范,
接口设计

取列表
取某一条数据
新增一个模版
更新指定的模版
删除指定模版
数据库设计:
REST的最佳实践:
- 充分理解并使用HTTP请求
- 使用API测试工具而非浏览器测试接口
- 合适的文档生成工具,输出API文档
- REST只是一个规范,适合的才是最好的
- 找一个好的框架胜过自己造轮子GraphQ
1.4.3. Web Server的测试
测试需要知道的:
编写测试代码的时间远比编写大妈时间要长
更多的测试代码代表着更多bug出现概率
测试代码的组织和维护缺乏工具框架,需要手动编写
基于测试的思路容易走向系统的国度设计,关注点脱离主流
测试的原因:
测试的价值毋庸置疑,但要划清界限,那些需要测试
TDD只适合种狗自己代码的场景,不要盲目尝试
不要着急实现测试细节,只关注输入输出,先开始轻量测试
挑选适合的测试框架,避免做无意义的“编程卡顿”
最佳实践FIRST原则
Fast 快速执行
Independent 不依赖环境和顺序,有自己的3A环节
Repeatable 一次执行和多次执行结果相同
Self-Valid 测试要给是否通过,检验结果
Through 尽量覆盖所有应用场景
REST接口的测试
mocha框架,同类还有ava、jasmine、tap
使用supertest做客户端代理,向服务器发请求
chai断言库,配合mocha编写单测
在钩子中初始化服务器环境,种植数据库数据,处理掉require混存
基准测试和压力测试
使用benchmark 对核心代码进行基准测试
根据服务业务场景和经验估算业务访问量PV
使用ab对服务的吞吐量、响应时间、并发数进行测试。
预估服务性能和资源

- 单机QPS = 总请求数 / (进程总数 * 请求时间),从压测得到
- 峰值时间QPS = (总PV数 80%)/(每天秒数 20%) = pv(w) / 2.16
- 单台机器总PV = QPS 3600 8
- 需要的机器 = 峰值时间QPS / 单机QPS